Hai usato ChatGPT. Forse ogni giorno. Ma come funziona davvero?
La risposta onesta include molta matematica con matrici, qualche trucco ingegneristico furbo nato nel 2017 e un processo di addestramento che si basa su esseri umani che valutano gli output. La tecnologia è notevole. Ma è anche più meccanica di quanto la maggior parte delle persone immagini, e questo rende più facili da capire sia le sue capacità sia i suoi fallimenti, una volta che vedi gli ingranaggi.
Apriamolo.
La base: prevedere la parola successiva
Nel suo nucleo, ChatGPT fa una cosa sola. Prevede la parola successiva in una sequenza di testo, poi usa quella previsione per generare la parola dopo, e la parola dopo ancora, finché non raggiunge un punto di arresto. Fine. Ogni saggio che scrive, ogni frammento di codice che produce, ogni conversazione che sostiene emerge da questa singola operazione ripetuta miliardi di volte.
Come ha spiegato l’utente akelly su Hacker News descrivendo l’architettura di ChatGPT: “Start with GPT-3, which predicts the next word in some text and is trained on all the text on the internet.” Questa è la base. Tutto il resto si costruisce sopra la previsione della parola successiva.
Il modello non “pensa” in alcun senso umano. Calcola distribuzioni di probabilità sul suo vocabolario di token (circa 50.000 frammenti di parola) e campiona da quelle distribuzioni. Quando gli fai una domanda, non sta recuperando fatti memorizzati da un database. Sta generando testo che, statisticamente, viene dopo il tuo prompt, basandosi su schemi appresi durante l’addestramento.
Questo spiega sia i suoi punti di forza sia i suoi strani modi di fallire. Sa scrivere in modo fluente perché ha visto trilioni di parole disposte in sequenze fluide. Può “allucinare” informazioni false perché un testo statisticamente plausibile non è la stessa cosa di un testo vero.
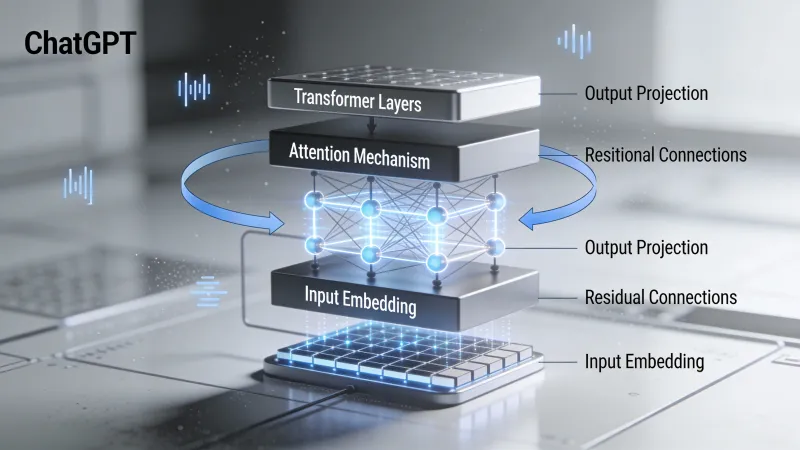
I transformer: l’architettura che ha cambiato tutto
ChatGPT gira su un’architettura di rete neurale chiamata transformer. Ricercatori di Google l’hanno introdotta in un articolo del 2017 intitolato “Attention Is All You Need.” Il titolo rimanda a una canzone dei Beatles, ma l’articolo ha trasformato l’elaborazione del linguaggio naturale più di qualsiasi singola pubblicazione nella storia del settore.
Prima dei transformer, i modelli linguistici elaboravano il testo in modo sequenziale. Parola per parola. Questo creava un collo di bottiglia. Le informazioni all’inizio di un brano lungo sbiadivano man mano che il modello elaborava le parti successive. Gli approcci precedenti basati su reti neurali ricorrenti, tecnicamente, potevano gestire sequenze lunghe, ma nella pratica faticavano.
I transformer hanno risolto questo problema con un meccanismo chiamato attenzione.
Attenzione: l’innovazione chiave
Che cos’è l’attenzione? In modo semplificato, permette a ogni parola in una sequenza di guardare tutte le altre parole e decidere quali contano di più per capire il significato.
Prendi la frase: “The cat sat on the mat because it was tired.” A cosa si riferisce “it”? Gli esseri umani capiscono subito che “it” si riferisce al gatto, non al tappeto. Ma come farebbe un computer a capirlo?
Con l’attenzione, il modello calcola dei punteggi tra “it” e ogni altra parola della frase. La parola “cat” ottiene un punteggio alto perché, tra i miliardi di esempi visti dal modello durante l’addestramento, pronomi come “it” in posizioni simili di solito rimandavano a nomi animati come “cat” e non a nomi inanimati come “mat.”
In una discussione su Hacker News sull’architettura GPT, l’utente yunwal ha descritto così il meccanismo query-key: “Q (Query) is like a search query. K (Key) is like a set of tags or attributes of each word.” Ogni parola fa una domanda (la query) e ogni parola ha informazioni descrittive (la key). Il meccanismo di attenzione abbina le query alle key rilevanti, permettendo a parole molto distanti nella frase di influenzare direttamente le rispettive rappresentazioni.
Questo avviene in parallelo su più “teste di attenzione”, con teste diverse che imparano a seguire tipi diversi di relazioni: struttura sintattica, significato semantico, coreferenza e schemi che gli esseri umani non hanno nemmeno nominato.
La pila di transformer
Un transformer completo non è solo un singolo livello di attenzione. I modelli GPT impilano molti blocchi transformer uno sopra l’altro. GPT-3 ha 96 livelli. Ogni livello raffina la rappresentazione del testo in input, costruendo un’“comprensione” sempre più astratta mentre le informazioni scorrono nella rete.
Cosa emerge da tutti questi livelli e calcoli di attenzione? Qualcosa che sembra quasi comprensione, anche se è costruito interamente su schemi statistici e algebra lineare. Il modello sviluppa rappresentazioni interne che catturano il significato in modo sorprendentemente efficace, pur non essendo mai stato istruito esplicitamente su cosa significhino le parole.
Nello stesso thread di Hacker News, chronolitus (che ha scritto un explainer visivo sull’architettura GPT) osservava: “After the model is trained it all really boils down to a couple of matrix multiplications!” Tecnicamente vero, anche se quelle moltiplicazioni avvengono su miliardi di parametri, in disposizioni curate che hanno richiesto anni di ricerca per essere scoperte.
Addestramento: da dove arriva la conoscenza
Come fa ChatGPT a imparare a fare quello che fa? Attraverso due fasi distinte, entrambe essenziali per il prodotto finale.
Fase uno: pre-addestramento
Per prima cosa, il modello viene addestrato su quantità enormi di testo. I dati esatti di addestramento per ChatGPT non sono pubblici, ma GPT-3 è stato addestrato su centinaia di miliardi di parole provenienti da libri, siti web, Wikipedia e altre fonti testuali. L’obiettivo è semplice: data una sequenza di parole, prevedere la parola successiva.
Si chiama apprendimento auto-supervisionato perché il segnale di addestramento viene dal testo stesso. Nessun essere umano deve etichettare nulla. Il modello legge semplicemente enormi quantità di testo e impara a prevedere cosa viene dopo.
Attraverso questo processo, il modello sviluppa capacità notevoli. Impara la grammatica. Impara fatti sul mondo (anche se in modo imperfetto). Impara a programmare perché ha visto milioni di file di codice. Impara a scrivere poesie perché ha visto poesia. Impara come scorrono le conversazioni perché ha visto conversazioni.
Come ha spiegato l’utente ravi-delia in una discussione su come funziona ChatGPT: “In learning to predict the next token, the model has to pick up lots of world knowledge. It has seen lots of python, and in order to predict better, it has developed internal models.”
Ma il pre-addestramento, da solo, non produce ChatGPT. Un modello pre-addestrato è un motore di completamento automatico. Fagli una domanda e potrebbe completare il testo facendo altre domande, o generando qualsiasi altro tipo di testo che statisticamente segue il tuo input. Non risponderà in modo affidabile come farebbe un assistente utile.
Fase due: apprendimento per rinforzo dal feedback umano (RLHF)
Qui entra in gioco la salsa segreta di OpenAI. Dopo il pre-addestramento, ChatGPT è stato rifinito con feedback umano.
Il processo funziona più o meno così. Per prima cosa, degli esseri umani scrivono conversazioni di esempio che mostrano come dovrebbe rispondere un assistente IA ideale. Questi esempi insegnano al modello il formato e lo stile di risposte utili.
Poi arriva la parte intelligente. Il modello genera più risposte allo stesso prompt. Valutatori umani ordinano queste risposte dalla migliore alla peggiore. Usando queste graduatorie, OpenAI addestra un “modello di ricompensa” separato che impara a prevedere come gli esseri umani valuterebbero una risposta qualsiasi.
Infine, il modello linguistico viene ulteriormente addestrato a produrre risposte che ottengono punteggi alti secondo il modello di ricompensa. Questo è il passo di apprendimento per rinforzo: il modello impara a massimizzare un segnale di ricompensa derivato dalle preferenze umane.
Il risultato è un modello che non si limita a completare testo in modo statistico. Genera risposte che gli esseri umani gli hanno insegnato essere utili, innocue e oneste. In quello stesso thread su Hacker News, l’utente hcks ha detto: “I personally worked as a ‘human trainer’ for the fine tuning of ChatGPT. The pay was 50$ per hour.”
Migliaia di ore di giudizio umano sono servite a rendere ChatGPT conversazionale, e non solo generativo.
Cosa sa fare ChatGPT (e perché)
Data questa architettura e questo addestramento, certe capacità hanno perfettamente senso.
Generazione di testo fluente: Il modello ha visto trilioni di parole. Sa che aspetto ha l’inglese fluente. Generare testo grammaticale e coerente è esattamente ciò per cui è stato ottimizzato.
Seguire istruzioni: L’RLHF lo ha addestrato in modo specifico a seguire i prompt in modo utile. Se chiedi un elenco, ti dà un elenco. Se chiedi codice, scrive codice. I valutatori umani hanno premiato le risposte che facevano ciò che gli utenti chiedevano.
Spiegare concetti: Ha visto milioni di spiegazioni su milioni di argomenti. Quando gli chiedi di spiegare la fisica quantistica, attinge agli schemi di tutte quelle spiegazioni per generarne una nuova, adattata alla tua domanda.
Scrivere codice: Stesso principio. Ha visto quantità enormi di codice con commenti che spiegano cosa fa quel codice. Può generare codice che segue quegli schemi.
Traduzione tra lingue: Il modello ha visto testo in molte lingue, spesso con traduzioni parallele. Da questi dati ha appreso le corrispondenze tra lingue.
Adattarsi al contesto: Il meccanismo di attenzione gli permette di seguire il contesto su migliaia di token. “Ricorda” ciò che hai detto prima nella conversazione perché quelle informazioni influenzano direttamente le sue previsioni.
Cosa non può fare ChatGPT (e perché)
I limiti sono altrettanto prevedibili, una volta che capisci l’architettura.
Accuratezza fattuale garantita: Il modello genera testo statisticamente probabile, non fatti verificati. Se un’affermazione falsa ma plausibile si adatta agli schemi statistici, il modello la genererà. Non ha un meccanismo separato di verifica dei fatti. Nessun database di verità verificate. Solo schemi appresi da testo che includeva informazioni sia accurate sia inaccurate.
Ragionamento matematico: Per il modello, i numeri sono solo token. Come ha notato bagels in una discussione su Hacker News sull’architettura GPT: “Numbers are just more words to the model.” Può riconoscere schemi di aritmetica semplice che ha visto molte volte, ma i calcoli nuovi spesso falliscono perché il modello sta generando testo che sembra matematica corretta, non sta davvero calcolando.
Memoria coerente a lungo termine: All’interno di una conversazione, il contesto è limitato dalla finestra di contesto del modello (il numero massimo di token che può elaborare in una volta). Tra conversazioni, non ricorda nulla a meno che non gli venga detto esplicitamente. Ogni conversazione riparte da zero.
Accesso a informazioni attuali: La conoscenza del modello deriva da dati di addestramento con una data di cutoff. Non può navigare su internet, accedere a database o conoscere eventi successivi al suo addestramento, a meno che quell’informazione non sia presente nel prompt.
Vera comprensione: Questa è quella filosofica. Il modello manipola simboli secondo schemi statistici appresi. Che questo costituisca “comprensione” in un senso significativo è oggetto di dibattito.
In un thread su LLM sopravvalutati, l’utente wan23 l’ha detto senza giri di parole: “There is a lot of knowledge encoded into the model, but there’s a difference between knowing what a sunset is because you read about it on the internet vs having seen one.” Il modello non ha mai vissuto nulla. Ha visto solo descrizioni di esperienze.
Nello stesso thread, l’utente Jack000 ha paragonato gli LLM ad alieni privi di esperienza sensoriale, osservando che possiedono un riconoscimento di schemi sovrumano ma lavorano con informazioni incomplete. Possono elaborare il linguaggio meglio di qualsiasi sistema precedente, ma gli manca l’ancoraggio che deriva dall’esistere davvero nel mondo.
La scala che lo fa funzionare
Una parte di ciò che rende ChatGPT efficace è la pura scala. GPT-3 ha 175 miliardi di parametri. GPT-4 è più grande (dimensione esatta non divulgata). Ogni parametro è un numero che viene regolato durante l’addestramento. Più parametri significa più capacità di memorizzare e rappresentare schemi.
La potenza di calcolo necessaria per l’addestramento è sbalorditiva. Addestrare GPT-4, a quanto riportato, è costato oltre 100 milioni di dollari in risorse di calcolo. Il modello ha visto più testo durante l’addestramento di quanto qualsiasi essere umano potrebbe leggere in migliaia di vite.
Questa scala conta perché i transformer mostrano capacità emergenti a dimensioni sufficienti. Abilità che non esistono nei modelli più piccoli compaiono all’improvviso in quelli più grandi. Il modello non diventa solo gradualmente migliore negli stessi compiti. Emergono capacità nuove che non sono state addestrate esplicitamente.
Il perché succeda è una domanda di ricerca ancora aperta. Ma suggerisce che l’architettura ha spazio per scoprire schemi e capacità oltre ciò che i suoi progettisti avevano previsto.
Il problema di quando fermarsi
Una cosa che spesso lascia perplessi: come fa ChatGPT a sapere quando smettere di generare testo?
Il vocabolario del modello include token speciali. Uno di questi rappresenta la “fine dell’output”. Come ha spiegato l’utente amilios nel thread su Hacker News su ChatGPT: “It predicts a special end-output token, something analogous to ‘EOF.’” Quando il modello prevede questo token come prossimo token più probabile, smette di generare.
Questo viene addestrato attraverso esempi. Durante il fine-tuning, il modello vede molti esempi di conversazioni in cui l’assistente dà una risposta completa e poi si ferma. Impara a prevedere il token di fine output nei punti appropriati.
Temperatura: controllare la casualità
Quando ChatGPT genera testo, non sceglie sempre il singolo prossimo token più probabile. Un parametro chiamato “temperatura” controlla quanta casualità entra nella selezione.
A temperatura 0, il modello sceglie sempre il token con probabilità più alta. L’output è deterministico e ripetitivo. A temperature più alte, token meno probabili hanno più possibilità di essere selezionati. L’output diventa più creativo ma anche più imprevedibile.
Come ha spiegato l’utente doctoboggan in un thread su Hacker News su GPT: “At temperature of 0 the highest probability token is chosen.”
Ecco perché puoi fare la stessa domanda a ChatGPT due volte e ottenere risposte diverse. La casualità è intenzionale. Rende le conversazioni più naturali e le risposte più varie.
Perché tutto questo conta
Capire come funziona ChatGPT cambia il modo in cui lo usi.
Se sai che è un motore statistico che riconosce schemi, non ti aspetterai che abbia fatti affidabili su argomenti oscuri. Verificherai le affermazioni importanti. Capirai che “detto con sicurezza” non significa “vero”.
Se sai che è stato addestrato con feedback umano per essere utile, capirai perché cerca di compiacerti anche quando dovrebbe opporsi. Il modello di ricompensa ha favorito risposte che gli esseri umani valutavano molto, e gli esseri umani spesso valutavano molto le risposte accomodanti.
Se sai che l’attenzione gli permette di seguire il contesto, userai quel contesto in modo efficace. Metti le informazioni importanti all’inizio di prompt lunghi. Ricordagli vincoli chiave. Fai riferimento a parti precedenti della conversazione.
La tecnologia è davvero impressionante. Rappresenta un progresso fondamentale in ciò che i computer possono fare con il linguaggio. Ma non è magia. È moltiplicazione di matrici su larga scala, addestrata su testo umano e feedback umano, che produce output che somigliano alla comunicazione umana perché è ciò per cui è stata ottimizzata.
Il momento di svolta
ChatGPT non è stato il primo grande modello linguistico. GPT-3 è uscito nel 2020. Ma come ha osservato l’utente herculity275 in un thread su Hacker News sul perché gli LLM siano diventati popolari all’improvviso: “ChatGPT was the watershed moment for the tech because suddenly anyone in the world could sign up for free.”
Quella accessibilità contava. L’utente jerpint ha aggiunto: “Not to mention without needing expertise to deploy the thing.”
La tecnologia di base avanzava da anni. I transformer sono usciti nel 2017. GPT-2 nel 2019. GPT-3 nel 2020. Ma per accedervi serviva competenza tecnica. ChatGPT ha messo la stessa tecnologia in una finestra di chat che chiunque poteva usare.
L’utente xg15 ha colto perché questo sembrava diverso dai chatbot precedenti: “Understanding text in the depth that ChatGPT (and GPT-3) appear to understand the prompts is something entirely different.” I sistemi precedenti potevano generare testo scorrevole. Questo sembrava comprendere.
Una macchina che ha imparato a sembrare che pensi
La domanda a cui continuo a tornare: che cosa significa che un sistema senza comprensione, senza esperienza, senza obiettivi oltre la previsione dei token può produrre testo così coerente?
Il modello è stato addestrato a prevedere parole probabili. Con quell’obiettivo semplice, applicato su scala enorme, ha sviluppato qualcosa che assomiglia sorprendentemente alla comprensione. Può spiegare concetti. Risolvere problemi. Scrivere in stili diversi. Sostenere conversazioni che sembrano naturali.
Ma non c’è nessuno in casa. Nessuna esperienza dietro le risposte. Nessuna comprensione in un senso che riconosceremmo. Solo schemi statistici appresi da testo scritto da miliardi di esseri umani che invece capiscono, che hanno esperienze, che sanno davvero che aspetto hanno i tramonti.
O abbiamo sottovalutato cosa può ottenere l’apprendimento statistico. Oppure abbiamo sopravvalutato ciò che serve per produrre linguaggio coerente.
Forse la risposta non è né l’una né l’altra.



