Você já usou o ChatGPT. Talvez todos os dias. Mas como ele funciona de verdade?
A resposta honesta envolve muita matemática de matrizes, alguns truques de engenharia bem espertos de 2017 e um processo de treinamento que depende de humanos avaliando respostas. A tecnologia é notável. E também é mais mecânica do que a maioria das pessoas imagina — o que torna tanto as capacidades quanto as falhas mais fáceis de entender quando você enxerga as engrenagens.
Vamos abrir isso por dentro.
A base: prever a próxima palavra
No fundo, o ChatGPT faz uma coisa só. Ele prevê a próxima palavra em uma sequência de texto e, em seguida, usa essa previsão para gerar a palavra seguinte, e a seguinte, e a seguinte, até chegar a um ponto de parada. É isso. Todo ensaio que ele escreve, todo trecho de código que ele produz, toda conversa que ele mantém emerge dessa única operação, repetida bilhões de vezes.
Como o usuário akelly explicou no Hacker News ao descrever a arquitetura do ChatGPT: “Start with GPT-3, which predicts the next word in some text and is trained on all the text on the internet.” Essa é a base. Todo o resto se constrói em cima da previsão da próxima palavra.
O modelo não “pensa” em nenhum sentido humano. Ele calcula distribuições de probabilidade sobre seu vocabulário de tokens (cerca de 50.000 fragmentos de palavras) e amostra dessas distribuições. Quando você faz uma pergunta, ele não está recuperando fatos armazenados em um banco de dados. Ele está gerando texto que, estatisticamente, vem a seguir do que você escreveu, com base em padrões que aprendeu durante o treinamento.
Isso explica tanto os pontos fortes quanto os modos estranhos de falha. Ele escreve com fluência porque viu trilhões de palavras organizadas em sequências fluentes. Ele alucina informações falsas porque texto estatisticamente plausível não é a mesma coisa que texto verdadeiro.
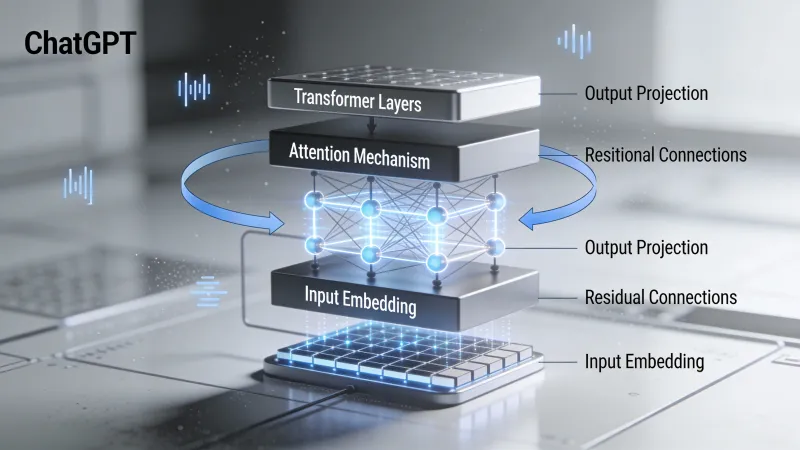
Transformers: a arquitetura que mudou tudo
O ChatGPT roda em uma arquitetura de rede neural chamada transformer. Pesquisadores do Google a introduziram em um artigo de 2017 intitulado “Attention Is All You Need”. O título faz referência a uma música dos Beatles, mas o artigo transformou o processamento de linguagem natural mais do que qualquer publicação isolada na história do campo.
Antes dos transformers, modelos de linguagem processavam texto de forma sequencial. Palavra por palavra. Isso criava um gargalo. Informações do início de uma passagem longa iam se apagando conforme o modelo processava as partes finais. Abordagens anteriores com redes neurais recorrentes, em tese, conseguiam lidar com sequências longas, mas na prática tropeçavam.
Os transformers resolveram isso com um mecanismo chamado atenção.
Atenção: a grande inovação
O que é atenção? Em um nível simplificado, ela permite que cada palavra em uma sequência “olhe” para todas as outras palavras e decida quais importam mais para entender seu significado.
Considere a frase: “O gato sentou no tapete porque ele estava cansado.” A que “ele” se refere? Humanos sabem na hora que “ele” se refere ao gato, não ao tapete. Mas como um computador descobriria isso?
Com atenção, o modelo calcula pontuações entre “ele” e todas as outras palavras da frase. A palavra “gato” recebe uma pontuação alta de atenção porque, ao longo dos bilhões de exemplos que o modelo viu no treinamento, pronomes nessa posição, em frases parecidas, normalmente retomavam substantivos animados como “gato”, e não objetos inanimados como “tapete”.
Em uma discussão no Hacker News sobre a arquitetura do GPT, o usuário yunwal descreveu o mecanismo de query-key assim: “Q (Query) is like a search query. K (Key) is like a set of tags or attributes of each word.” Cada palavra faz uma pergunta (a query) e cada palavra tem informação descritiva (a key). O mecanismo de atenção casa queries com keys relevantes, permitindo que palavras distantes em uma frase influenciem diretamente as representações umas das outras.
Isso acontece em múltiplas “cabeças de atenção” ao mesmo tempo, com cabeças diferentes aprendendo a rastrear diferentes tipos de relação: estrutura sintática, significado semântico, correferência e padrões que humanos ainda nem batizaram.
A pilha de transformers
Um transformer completo não é apenas uma camada de atenção. Modelos GPT empilham muitos blocos transformer um em cima do outro. O GPT-3 tem 96 camadas. Cada camada refina a representação do texto de entrada, construindo um entendimento cada vez mais abstrato conforme a informação flui pela rede.
O que surge de todas essas camadas e cálculos de atenção? Algo que parece quase compreensão — mesmo sendo construído inteiramente de padrões estatísticos e álgebra linear. O modelo desenvolve representações internas que capturam significado de forma surpreendentemente boa, apesar de nunca ter sido explicitamente ensinado sobre o que as palavras significam.
No mesmo fio do Hacker News, chronolitus (que escreveu um explicador visual da arquitetura do GPT) observou: “After the model is trained it all really boils down to a couple of matrix multiplications!” Tecnicamente, é verdade — só que essas multiplicações acontecem por bilhões de parâmetros, em arranjos cuidadosos que levaram anos de pesquisa para serem descobertos.
Treinamento: de onde vem o conhecimento
Como o ChatGPT aprende a fazer o que faz? Em duas fases distintas — e ambas essenciais para o produto final.
Fase um: pré-treinamento
Primeiro, o modelo é treinado com quantidades massivas de texto. Os dados exatos de treinamento do ChatGPT não são públicos, mas o GPT-3 foi treinado com centenas de bilhões de palavras vindas de livros, sites, Wikipedia e outras fontes textuais. O objetivo é simples: dada uma sequência de palavras, prever a próxima palavra.
Isso se chama aprendizado auto-supervisionado porque o sinal de treinamento vem do próprio texto. Ninguém precisa rotular nada manualmente. O modelo só lê quantidades enormes de texto e aprende a prever o que vem a seguir.
Por esse processo, o modelo ganha capacidades notáveis. Aprende gramática. Aprende fatos sobre o mundo (embora de modo imperfeito). Aprende a programar porque viu milhões de arquivos de código. Aprende a escrever poesia porque viu poesia. Aprende como conversas fluem porque viu conversas.
Como o usuário ravi-delia explicou em uma discussão sobre como o ChatGPT funciona: “In learning to predict the next token, the model has to pick up lots of world knowledge. It has seen lots of python, and in order to predict better, it has developed internal models.”
Mas só o pré-treinamento não produz o ChatGPT. Um modelo pré-treinado é um motor de autocompletar. Faça uma pergunta e ele pode completar seu texto fazendo mais perguntas, ou gerando qualquer outro tipo de texto que estatisticamente venha a seguir do que você forneceu. Ele não vai responder de forma confiável como um assistente prestativo faria.
Fase dois: aprendizado por reforço com feedback humano (RLHF)
É aqui que entra o molho secreto da OpenAI. Depois do pré-treinamento, o ChatGPT foi ajustado com base em feedback humano.
O processo funciona mais ou menos assim. Primeiro, humanos escrevem conversas de exemplo demonstrando como um assistente de IA ideal deveria responder. Esses exemplos ensinam ao modelo o formato e o estilo de respostas úteis.
Depois vem a parte esperta. O modelo gera várias respostas para a mesma instrução. Avaliadores humanos classificam essas respostas da melhor para a pior. Com esses rankings, a OpenAI treina um “modelo de recompensa” separado, que aprende a prever como humanos avaliariam qualquer resposta.
Por fim, o modelo de linguagem é treinado mais um pouco para produzir respostas que pontuam alto segundo o modelo de recompensa. Essa é a etapa de aprendizado por reforço: o modelo aprende a maximizar um sinal de recompensa derivado das preferências humanas.
O resultado é um modelo que não apenas completa texto de forma estatística. Ele gera respostas que humanos ensinaram a ele a serem úteis, inofensivas e honestas. Nesse mesmo fio do Hacker News, o usuário hcks comentou: “I personally worked as a ‘human trainer’ for the fine tuning of ChatGPT. The pay was 50$ per hour.”
Milhares de horas de julgamento humano foram investidas para tornar o ChatGPT conversacional, e não apenas gerativo.
O que o ChatGPT consegue fazer (e por quê)
Dada essa arquitetura e esse treinamento, certas capacidades fazem sentido.
Geração de texto fluente: O modelo viu trilhões de palavras. Ele sabe como o inglês fluente se parece. Gerar texto gramatical e coerente é exatamente aquilo para o qual ele foi otimizado.
Seguir instruções: O RLHF o treinou especificamente para seguir prompts de forma útil. Quando você pede uma lista, ele entrega uma lista. Quando você pede código, ele escreve código. Avaliadores humanos recompensavam respostas que faziam o que os usuários pediam.
Explicar conceitos: Ele viu milhões de explicações de milhões de assuntos. Quando você pede que ele explique física quântica, ele se apoia em padrões dessas explicações para gerar uma nova, ajustada à sua pergunta.
Escrever código: Mesma ideia. Ele viu quantidades enormes de código com comentários explicando o que o código faz. Ele consegue gerar código que segue esses padrões.
Tradução entre idiomas: O modelo viu textos em muitos idiomas, muitas vezes com traduções paralelas. Ele aprendeu correspondências entre línguas a partir desses dados.
Adaptar-se ao contexto: O mecanismo de atenção permite acompanhar o contexto ao longo de milhares de tokens. Ele “lembra” o que você disse antes na conversa porque essa informação influencia diretamente suas previsões.
O que o ChatGPT não consegue fazer (e por quê)
As limitações são igualmente previsíveis quando você entende a arquitetura.
Precisão factual garantida: O modelo gera texto estatisticamente provável, não fatos verificados. Se uma afirmação falsa, mas plausível, se encaixar nos padrões estatísticos, o modelo vai gerá-la. Ele não tem um mecanismo separado de checagem de fatos. Não tem um banco de dados de verdades verificadas. Só padrões aprendidos a partir de texto que incluía informação correta e incorreta.
Raciocínio matemático: Para o modelo, números são apenas tokens. Como bagels observou em uma discussão no Hacker News sobre a arquitetura do GPT: “Numbers are just more words to the model.” Ele consegue reconhecer padrões de aritmética simples que viu muitas vezes, mas cálculos novos frequentemente falham porque o modelo está gerando texto que parece matemática correta — não calculando de fato.
Memória consistente de longo prazo: Dentro de uma conversa, o contexto é limitado pela janela de contexto do modelo (o número máximo de tokens que ele consegue processar de uma vez). Entre conversas, ele não lembra de nada a menos que seja explicitamente instruído. Cada conversa começa do zero.
Acesso a informações atuais: O conhecimento do modelo vem de dados de treinamento com uma data de corte. Ele não consegue navegar na internet, acessar bancos de dados nem saber sobre eventos depois do treinamento, a menos que essa informação seja fornecida na sua mensagem.
Compreensão de verdade: Esta é a filosófica. O modelo manipula símbolos de acordo com padrões estatísticos aprendidos. Se isso constitui “compreensão” em algum sentido significativo é debatido.
Em um fio sobre LLMs serem superestimados, o usuário wan23 foi direto: “There is a lot of knowledge encoded into the model, but there’s a difference between knowing what a sunset is because you read about it on the internet vs having seen one.” O modelo nunca vivenciou nada. Ele só viu descrições de experiências.
No mesmo fio, o usuário Jack000 comparou LLMs a alienígenas sem experiência sensorial, observando que eles têm reconhecimento de padrões super-humano, mas trabalham com informação incompleta. Eles processam linguagem melhor do que qualquer sistema anterior, mas lhes falta a ancoragem que vem de existir de fato no mundo.
A escala que faz isso funcionar
Parte do que torna o ChatGPT eficaz é pura escala. O GPT-3 tem 175 bilhões de parâmetros. O GPT-4 é maior (tamanho exato não divulgado). Cada parâmetro é um número que é ajustado durante o treinamento. Mais parâmetros significam mais capacidade de armazenar e representar padrões.
O poder de computação de treinamento é estonteante. Treinar o GPT-4 supostamente custou mais de $100 milhões em recursos computacionais. O modelo viu mais texto no treinamento do que qualquer humano poderia ler em milhares de vidas.
Essa escala importa porque transformers exibem capacidades emergentes quando atingem tamanho suficiente. Habilidades que não existem em modelos menores aparecem de repente em modelos maiores. O modelo não fica apenas incrementalmente melhor nas mesmas tarefas. Capacidades novas emergem, sem terem sido treinadas explicitamente.
Por que isso acontece ainda é uma questão aberta de pesquisa. Mas isso sugere que a arquitetura tem espaço para descobrir padrões e capacidades além do que seus projetistas anteciparam.
O problema de quando parar
Uma coisa que frequentemente confunde as pessoas: como o ChatGPT sabe quando parar de gerar texto?
O vocabulário do modelo inclui tokens especiais. Um deles representa “fim da saída”. Como o usuário amilios explicou no fio do Hacker News sobre o ChatGPT: “It predicts a special end-output token, something analogous to ‘EOF.’” Quando o modelo prevê esse token como o próximo token mais provável, ele para de gerar.
Isso é treinado por exemplos. Durante o ajuste fino, o modelo vê muitos exemplos de conversas em que o assistente dá uma resposta completa e então para. Ele aprende a prever o token de fim de saída nos pontos apropriados.
Temperatura: controlando a aleatoriedade
Quando o ChatGPT gera texto, ele nem sempre escolhe o próximo token mais provável. Um parâmetro chamado “temperatura” controla quanta aleatoriedade entra na seleção.
Em temperatura 0, o modelo sempre escolhe o token de maior probabilidade. A saída fica determinística e repetitiva. Em temperaturas mais altas, tokens menos prováveis têm mais chance de serem escolhidos. A saída fica mais criativa, mas também mais imprevisível.
Como o usuário doctoboggan explicou em um fio do Hacker News sobre GPT: “At temperature of 0 the highest probability token is chosen.”
É por isso que você pode fazer a mesma pergunta ao ChatGPT duas vezes e receber respostas diferentes. A aleatoriedade é intencional. Ela faz as conversas parecerem mais naturais e as respostas mais variadas.
Por que isso tudo importa
Entender como o ChatGPT funciona muda a forma como você o usa.
Se você sabe que ele é um motor estatístico de reconhecimento de padrões, não vai esperar que ele tenha fatos confiáveis sobre tópicos obscuros. Você vai verificar afirmações importantes. Vai entender que “dito com confiança” não significa “verdadeiro”.
Se você sabe que ele foi treinado com feedback humano para ser útil, vai entender por que ele tenta agradar mesmo quando deveria fazer objeções. O modelo de recompensa favoreceu respostas que humanos avaliaram bem — e humanos, com frequência, avaliaram bem respostas concordantes.
Se você sabe que a atenção permite rastrear contexto, vai usar esse contexto melhor. Coloque informação importante cedo em prompts longos. Relembre restrições principais. Faça referência a partes anteriores da conversa.
A tecnologia é realmente impressionante. Ela representa um avanço fundamental no que computadores conseguem fazer com linguagem. Mas não é mágica. É multiplicação de matrizes em escala, treinada em texto humano e feedback humano, produzindo saídas que se parecem com comunicação humana porque foi otimizada para produzir isso.
O momento de virada
O ChatGPT não foi o primeiro modelo de linguagem grande. O GPT-3 saiu em 2020. Mas, como o usuário herculity275 observou em um fio do Hacker News sobre por que LLMs de repente ficaram populares: “ChatGPT was the watershed moment for the tech because suddenly anyone in the world could sign up for free.”
Essa acessibilidade importou. O usuário jerpint acrescentou: “Not to mention without needing expertise to deploy the thing.”
A tecnologia por trás vinha avançando havia anos. Transformers saíram em 2017. GPT-2 em 2019. GPT-3 em 2020. Mas aquilo exigia conhecimento técnico para acessar. O ChatGPT colocou a mesma tecnologia em uma janela de chat que qualquer pessoa podia usar.
O usuário xg15 capturou por que isso pareceu diferente de chatbots anteriores: “Understanding text in the depth that ChatGPT (and GPT-3) appear to understand the prompts is something entirely different.” Sistemas anteriores conseguiam gerar texto fluente. Este parecia compreender.
Uma máquina que aprendeu a parecer que pensa
A pergunta a que eu sempre volto: o que significa que um sistema sem compreensão, sem experiência, sem objetivos além de prever tokens consiga produzir texto tão coerente?
O modelo foi treinado para prever palavras prováveis. Por meio desse objetivo simples, aplicado em escala enorme, ele desenvolveu algo que se parece muito com compreensão. Ele consegue explicar conceitos. Resolver problemas. Escrever em estilos diferentes. Manter conversas que parecem naturais.
Mas não tem ninguém ali. Não há experiência por trás das respostas. Não há compreensão em nenhum sentido que a gente reconheceria. Só padrões estatísticos aprendidos de texto escrito por bilhões de humanos que, sim, compreendem — que viveram coisas — que sabem como um pôr do sol realmente é.
Ou subestimamos o que o aprendizado estatístico consegue alcançar. Ou superestimamos o quanto produzir linguagem coerente exige.
Talvez a resposta não seja uma coisa nem outra.



